TD11 : Solveur
Dans ce TD, nous nous proposons d'ajouter de nouvelles fonctionnalités à notre projet afin de trouver la (ou les) solution(s) d'un jeu.
Exercice Préliminaire
Pour commencer ce TD, nous vous proposons d'étudier le principe de base d'un
solveur brute-force pour le problème très simple de la génération de mot
binaire de longeur N. Par exemple, 0101 est un mot binaire de longueur 4.
Même si ce problème est assez différent dans sa formulation du jeu qui nous
intéresse, le principe général qui est utilisé pour construire un solveur
brute-force est le même.
- Étudiez le code du programme binword.c, qui permet de
générer (et d'afficher) tous les mots binaires de taille
N=4. - Combien y-a-t'il de mots binaires de longueur
N? - Compilez et exécutez ce programme.
$ gcc -std=c99 -Wall binword.c
$ ./a.out
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
=> 16 words generated (of length 4)
- A quoi sert la variable
countdans la fonctiongenWords()? Pourquoi utilise-t-on un passage d'argument par adresse (avec un pointeur) ? - Modifiez ce programme pour qu'il traite des mots binaires de taille
N=6.
Vous aurez remarqué que ce code est très naïf, car il utilise des boucles
imbriquées pour explorer toutes les possibilités... Par conséquent, il n'est pas
facile de le généraliser pour toute valeur de N ! Une solution alternative
consiste à utiliser des fonctions récursives pour mener à bien l'exploration
combinatoire de tous les mots binaires.
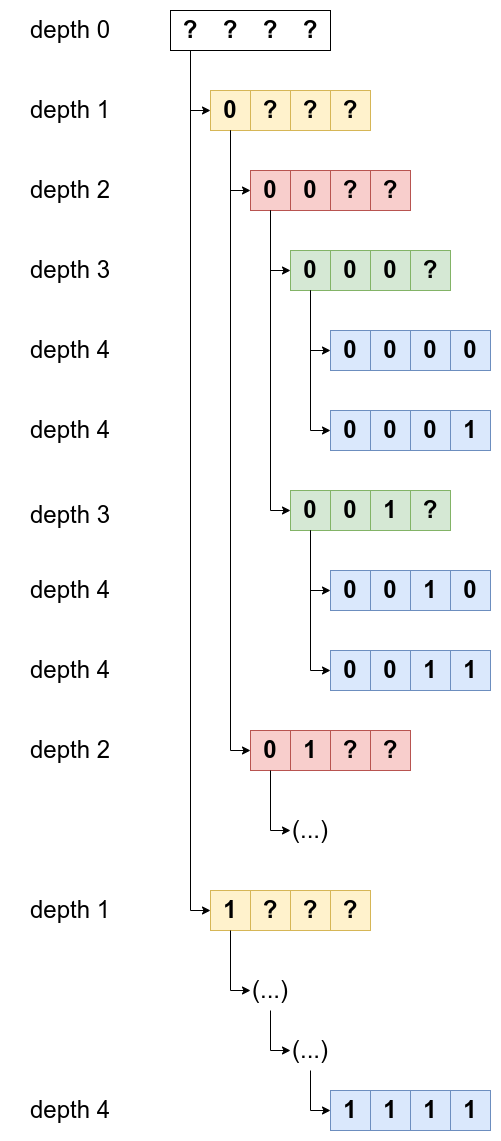
- Étudiez maintenant le code du programme binword_rec.c.
Testez-le et vérifiez qu'il fonctionne correctement pour
N=6ou tout autre valeur. - Vous remarquerez que ce programme utilise une seule et unique variable
word(de type tableau d'entiers) pour explorer récursivement toutes les possibilités. Dessinez sur le papier l'arbre d'appel des fonctions récursives pourN=4. Expliquez dans quel ordre cet arbre est parcouru ? En déduire l'ordre d'apparition des mots binaires générés. (cf. image) - Que se passe-t-il si
Ndevient très grand ? En supposant que le problème de tailleN=10mets 10 secondes pour être résolu, pouvez-vous prédire approximativement le temps qu'il faudra pour résoudre le problème de tailleN=11puis de tailleN=100? - Modifiez ce programme pour qu'il n'affiche que les mots binaires dont la somme
des bits vaut
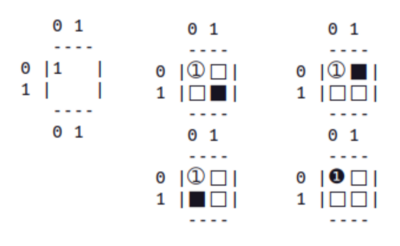
K. Voici à titre d'exemple les solutions pourN=4etK=2:
{kind=link}
0011
0101
0110
1001
1010
1100
Implémentation du solveur
Afin de réaliser notre solveur, il est demandé d'ajouter à la bibliothèque
game deux nouvelles fonctions game_nb_solutions() et game_solve(), qui
sont décrites dans la nouvelle version du fichier
game_tools.h que nous vous fournissons.
Notez que le code de ces deux fonctions est très similaire, car dans un cas il faut trouver toutes les solutions (pour les dénombrer) et dans l'autre il suffit de s'arrêter à la première solution trouvée.
- Commencez par écrire une fonction qui affiche toutes les solutions d'un jeu dans votre terminal.
- Pour ce faire, on peut s'inspirer du code de l'exercice préliminaire en
remarquant qu'il est possible de linéariser la grille 2D de notre jeu pour la
voir comme un mot binaire qui contient soit une case white (
0), soit une case black (1). Voici par exemple, la solution du jeu par défaut vue comme un mot binaire :00100|00101|11100|11000|11110. Bien entendu, notre solveur devra manipuler non pas un mot binaire mais une variable de typegamepour tenir compte des valeurs imposées. La comparaison s'arrête là. - Quand la grille du jeu est entièrement remplie (par une séquence de coups), on
peut alors vérifier si on a trouvé une solution (ou non) en appelant la
fonction
game_won(). - Modifiez maintenant votre fonction pour implémenter les deux fonctions demandées, sans dupliquer le code.
- On peut évidemment imaginer de nombreuses optimisations à cette première version, mais il est fortement déconseillé de les implémenter trop tôt !
Par ailleurs, il est demandé de créer un nouvel exécutable game_solve, qui
respectera la syntaxe suivante :
$ ./game_solve <option> <input> [<output>]
- Le premier paramètre
<option>permet de choisir la fonctionnalité du programme. - Le deuxième paramètre
<input>correspond au nom du fichier en entrée contenant l'instance problème à résoudre (dans le format spécifié). - Le troisième paramètre
<output>correspond au nom du fichier en sortie contenant le résultat du programme. Ce dernier paramètre est optionnel, et si il est omis, le programme se contentera d'afficher le résultat sur la sortie standard.
Voici la description des deux fonctionnalités demandées, correspondant aux
options -s et -c :
- L'option
-spermet de chercher une solution au jeu<input>et de la sauvegarder dans le fichier<output>. S'il n'y a pas de solution pour ce jeu, le programme se contente de terminer avecEXIT_FAILUREcomme valeur de retour. Si plusieurs solutions existent pour un jeu donné, on se contente de retourner la première trouvée. - L'option
-cpermet de compter le nombre total de solutions possibles pour le jeu<input>et enregistre ce nombre dans le fichier<output>au format texte avec un retour à la ligne. S'il n'y a pas de solution, c'est la valeur 0 qu'il faut écrire dans le fichier.
Voici un exemple de fichier game_2x2.txt avec 4 solutions :
Nota Bene : On suppose que le jeu passé en <input> est vide, c'est-à-dire
sans couleur (EMPTY).
Travail à faire :
- Commencez par implémenter une version du solveur récursif la plus simple possible, sans optimisation.
- On travaillera la question des optimisations lors de la prochaine séance...
Optimisation du solveur
Un exemple de Solveur pour TSP
Pour commencer ce TD, nous vous proposons de regarder un exemple de solveur brute-force pour le problème du voyageur de commerce (ou TSP). Même si ce problème est assez différent dans sa formulation du jeu qui nous intéresse, le principe général pour construire votre solveur est le même.
- Commencez par récupérer ce code : https://github.com/orel33/tsp
- Survolez ce code pour en comprendre le fonctionnement. Commencez par regarder
les structures de données, la fonction
main(), puis la fonctiontsp_solve(), et en particulier l'organisation des appels récursifs. - Compilez ce projet avec
cmake. - Voici les différentes options disponibles du programme
solve:
$ ./solve -h
Usage: ./solve <options>
-l filename: load distance matrix [required]
-f first: set first city [default: 0]
-v: enable verbose mode
-d: enable debug mode
-o: enable solver optimization
-h: print usage
- Utilisez le programme
randompour générer dans un fichier une matrice de distance de taille 4. - Exécutez le solveur sur ce fichier, en affichant les différents chemins
trouvés lors de l'exploration (option
-v). Par exemple :
$ ./random 4 test0.txt
$ ./solve -l test0.txt -v
- Notre algorithme est naif et se contente d'explorer toutes les possibilités
pour chercher la meilleure. Essayez l''option
-dqui permet d'afficher la construction récursive des chemins lors de 'exploration. - Testez ensuite successivement avec différentes tailles de problème (et sans
l'option
-v). Vous pouvez mesurer le temps d’exécution avec la commandetime. Cela donne sur ma machine les résultats approximatifs suivants.
time ./solve -l test0.txt # taille 4 (2 ms)
- Recommencez avec un fichier de taille 8 (10 ms), de taille 9 (60 ms), de
taille 10 (530 ms), de taille 11 (6170 ms). Essayez de prédire le temps
d'exécution du problème de taille 12... (Indice : algorithme de complexité
(N-1)!) - L'option
-oillustre un exemple d'optimisation ; nous y reviendrons à la fin de ce TD.
Optimisation du Solveur TSP
Afin d'optimiser votre propre solveur, nous vous proposons de reprendre l'exemple TSP. Cela devrait illustrer les différentes techniques que vous pouvait envisager pour votre propre solveur : les optimisations du compilateur, l'optimisation de l'implémentation d'une fonction, et l'optimisation plus générale de l'algorithme du solveur.
- Reprenez le code du solveur TSP : https://github.com/orel33/tsp
- Compilez ce programme avec gcc avec l'option
-O0(pas d'optimisation du compilateur) et lancez plusieurs fois son exécution sur un problème de taille 10 avec la commandetime. En déduire un temps d'exécution moyen. - Recompilez ce programme avec l'option
-O3, et recommencez vos mesures. L'option-DNDEBUGpermet de supprimer lesassert(). Pourquoi ne faut-il pas utiliser l'option-vpour mesurer les performances du programme ? - Recompilez maintenant ce programme en
-g -O0et lancez-le avecvalgrinden utilisant l'option--tool=callgrindde façon à réaliser un profilage de son exécution. Cette commande produit alors une trace d'exécution dans le fichiercallgrind.out.<pid>. Attention, cela ralentit fortement l'exécution de votre programme.
valgrind --tool=callgrind ./solve -l test0.txt
- Il est ainsi possible d'analyser cette trace d'exécution avec un outil
graphique comme
kcachegrind. Sélectionnez la fonctionsolveTSPet affichez le Callee Map et le Call Graph avec les options% RelativeetRelative to Parent. Cela devrait ressembler à cette image. De plus, il est possible d'analyser directement le code source... En déduire la fonction qu'il faudrait optimiser en priorité ! Comment faire pour se passer de la boucle for dans la fonctionupdatePathDist()?
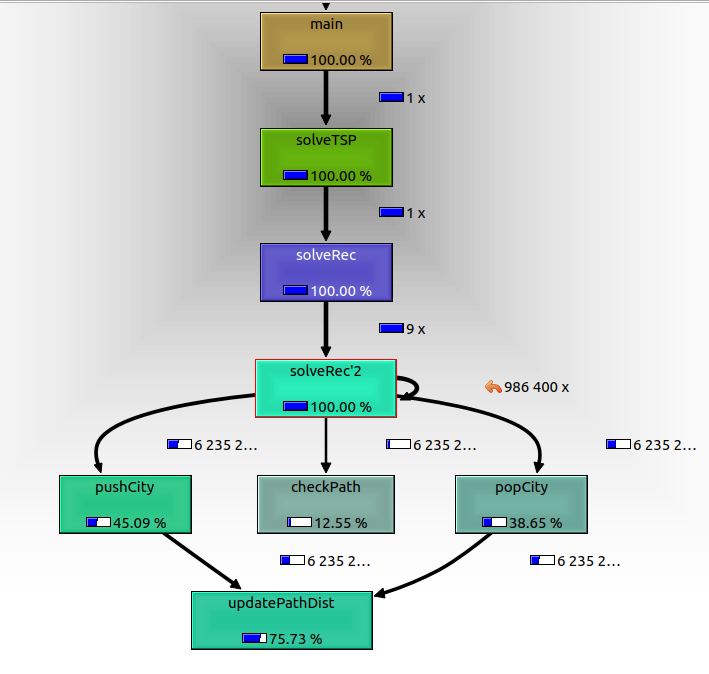{kind=link}
kcachegrind callgrind.out.<pid>
- Voici une alternative en mode texte, mais ce n'est pas très pratique ! Enlever
l'option
--auto=nopour voir le code annoté.
callgrind_annotate --auto=no callgrind.out.<pid>
- Une méthode classique d'optimisation algorithmique, appelée branch & bound,
consiste à limiter le nombre de chemins explorés dans l'arbre de recherche en
élaguant les branches qui ne pourront pas donner une meilleure solution que
celle-la déjà trouvée. Dans notre cas, c'est la fonction
checkPath()qui permet d'optimiser notre code... Recommencez les expériences avec l'option-oet comprenez ce que fait cette option !
Compilation en mode Debug ou Release
La compilation en mode Release (version optimisée) et en mode Debug (phase
de développement) correspondent souvent à des étapes différentes du cycle de vie
d'un logiciel, qui impliquent des options de compilation différentes... Il est
possible dans son fichier CMakeLists.txt de distinguer simplement ces deux
étapes de la façon suivante :
set(CMAKE_C_FLAGS "-Wall -std=c99") # options de compilation génériques
set(CMAKE_C_FLAGS_DEBUG "-g -O0 --coverage") # options de compilation en mode Debug
set(CMAKE_C_FLAGS_RELEASE "-O3") # options de compilation en mode Release
Pour choisir l'un ou l'autre de ces deux modes avec CMake, il suffit de
préciser le <MODE> de la façon suivante :
mkdir build ; cd build ; cmake -DCMAKE_BUILD_TYPE=<MODE> .. # <MODE> = DEBUG | RELEASE
Puis, on compile avec make VERBOSE=ON pour vérifier que les options de
compilation choisies sont bien prises en compte !
Accessoirement, Visual Studio Code vous permet de faire facilement le choix du mode de compilation CMake avec juste un clic souris, comme illustré sur l'image ci-dessous.
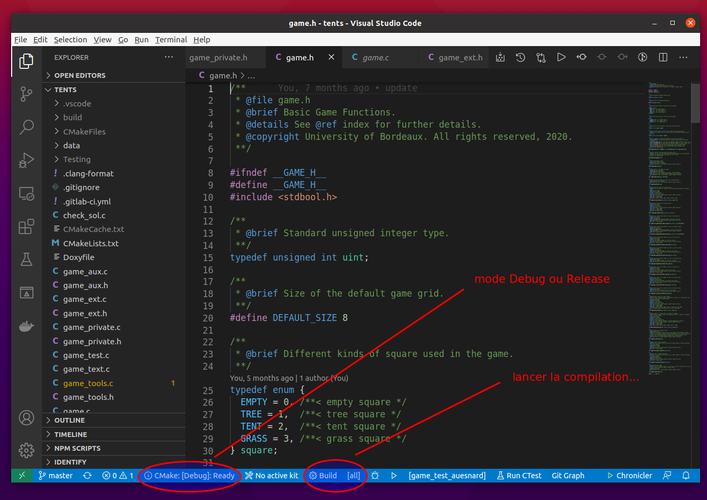
Plus d'info : https://vector-of-bool.github.io/docs/vscode-cmake-tools/getting_started.html
Optimisation de votre solveur
Une fois que vous avez réussi à implémenter une première version naïve mais correcte de votre solveur brute-force (sans optimisation a priori), il est temps de réfléchir à son optimisation pour réduire le temps d'exécution...
Considérons la commande suivante pour le jeu par défaut :
time ./game_solve -c default.txt
Nota Bene : Notre solveur mets 16 secondes sans optimisation pour trouver toutes les solutions (1 seule dans ce cas) et 0.68 secondes avec optimisation.
Testez votre solveur avec des jeux de plus en plus gros et différents niveaux d'optimisation. Gardez à l'esprit que les optimisations les plus simples sont souvent les plus efficaces ! En effet, une optimisation trop gourmande en calcul n'est pas forcément rentable...
Rendez votre code sur Moodle et gagnez le grand concours du solveur le plus rapide :-)